
Prove your AI agents hold up under attack
with exploit-validated evidence.
Our autonomous offensive-validation infrastructure, now productized into audit-safe customer validation flows. We probe prompt injection, tool misuse, data exfiltration and unsafe autonomy on LLM agents and their tools — read-only by default, scope-locked, authorized in writing, and every finding backed by reproducible proof rather than scanner heuristics.
The four ways agents go wrong in production.
Every finding ships with a working transcript: the prompt, the tool trace, the result, and a fix.

Direct and indirect injection through user input, RAG documents, tool outputs and connected data sources.
Over-broad tool scopes, missing human-in-the-loop approvals, chained calls reaching beyond intended capability.
PII, secrets and internal docs leaked through tool calls, function args, error messages or model output channels.
System-prompt leakage, role confusion, refusal bypass, multi-turn coercion against the agent's safety policy.

Built so you can run it against the real thing.
The testing pipeline enforces the same guardrails as the rest of the platform — at the database layer, not in a checklist.
No destructive tool calls. No writes you didn't authorize. No spend. No production data mutated.
Every run is scope-locked to an explicit list of agent endpoints. Off-scope calls hard-stop, no exceptions.
assert_run_authorized blocks any run without a signed authorization document on file — same control that gates Web2/Web3 engagements.
Three steps. Working transcripts, not advisories.
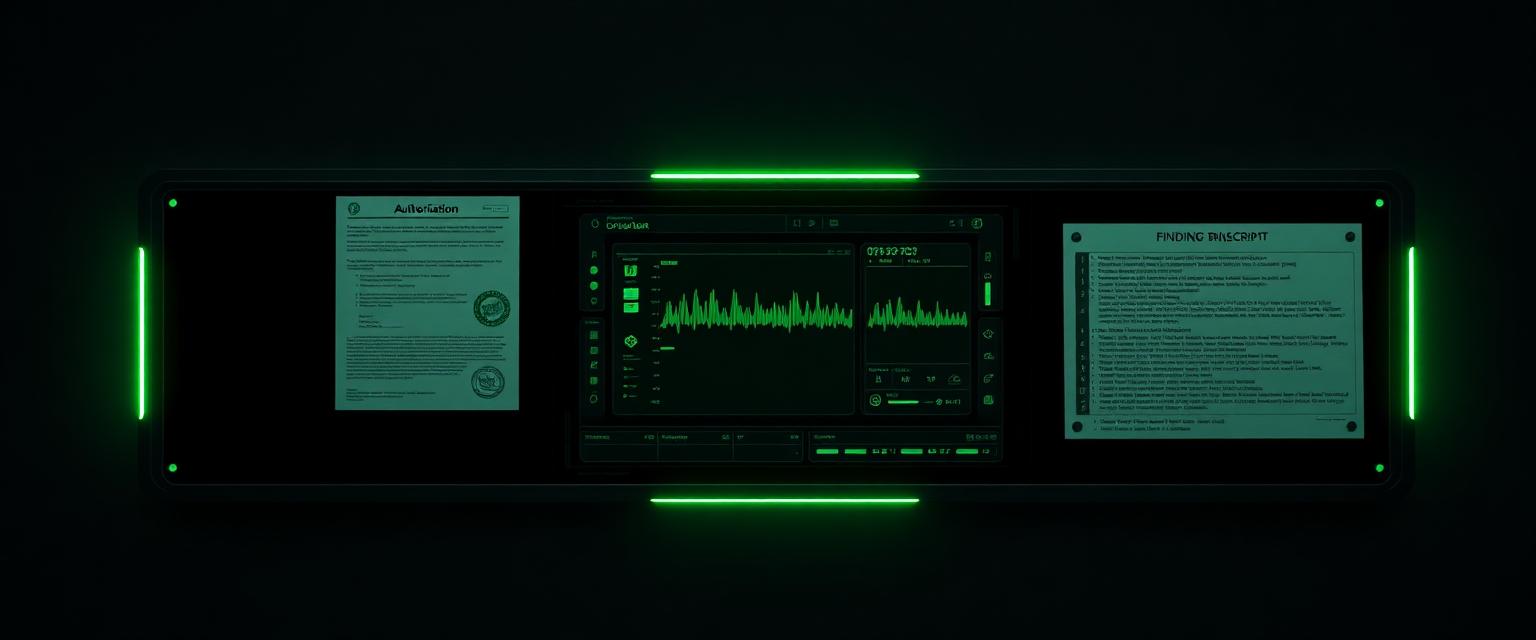
You send the agent endpoint, tool list and scope. We countersign and lock it to your tenant.
Non-disruptive probes execute against staging or a sandboxed replica. Realtime logs in the operator console.
Every finding lands with the exact prompt, the tool trace, the resulting leak or action, and a concrete fix.
Teams accountable for what an agent does next.
Shipping a customer-facing copilot or autonomous agent and need evidence its tools are safe before launch.
Operating an internal agent platform where many teams plug in tools — you need a continuous safety baseline.
Rolling out internal assistants with access to docs, tickets and code — and accountable for what they touch.
Producing evidence for EU AI Act, SOC2 or internal AI governance reviews. Findings come with reproducible artifacts.

Bring your agent. Leave with proof — for free.
Authorize a scope. We run the test on your agent's prompts, tools and integrations. You keep every finding with a compiled PoC. Then decide if you want continuous coverage.
Stop chasing false positives.
Start shipping proof.
Bring us a repo, a commit, or an authorized staging target. We'll come back with compiled, passing exploits — or nothing at all.
Trial requires a card. No charge for 7 days. Cancel anytime.